Inside Arbitrum
This document is a deep-dive explanation of Arbitrum’s design and the rationale for it. This isn’t API documentation, nor is it a guided tour of the code--look elsewhere for those. “Inside Arbitrum” is for people who want to understand Arbitrum’s design.
Why use Arbitrum?
Arbitrum is an L2 scaling solution for Ethereum, offering a unique combination of benefits:
- Trustless security: security rooted in Ethereum, with any one party able to ensure correct Layer 2 results
- Compatibility with Ethereum: able to run unmodified EVM contracts and unmodified Ethereum transactions
- Scalability: moving contracts’ computation and storage off of the main Ethereum chain, allowing much higher throughput
- Minimum cost: designed and engineered to minimize the L1 gas footprint of the system, minimizing per-transaction cost.
Some other Layer 2 systems provide some of these features, but to our knowledge no other system offers the same combination of features at the same cost.
The Big Picture
At the most basic level, an Arbitrum chain works like this:
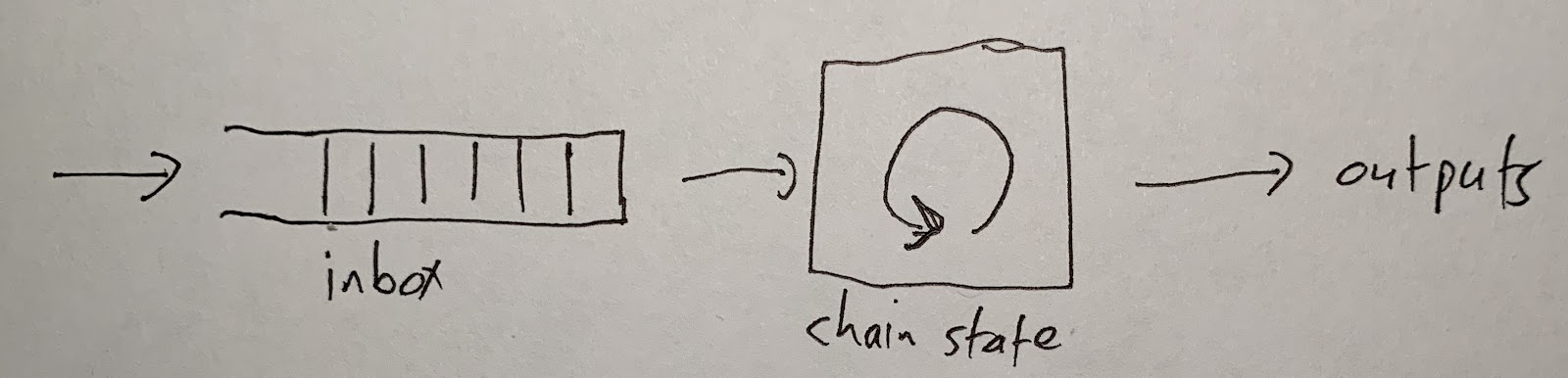
People and contracts put messages into the inbox. The chain reads the messages one at a time, and processes each one. This updates the state of the chain and produces some outputs.
If you want an Arbitrum chain to process a transaction for you, you need to put that transaction into the chain’s inbox. Then the chain will see your transaction, execute it, and produce some outputs: a transaction receipt, and any withdrawals that your transaction did.
Execution is deterministic -- which means that the chain’s behavior is uniquely determined by the contents of its inbox. Because of this, the result of your transaction is knowable as soon as your transaction has been put in the inbox. Any Arbitrum node will be able to tell you the result. (And you can run an Arbitrum node yourself if you want.)
All of the technical detail in this document is connected to this diagram. To get from this diagram to a full description of Arbitrum, we’ll need to answer questions like these:
- Who keeps track of the inbox, chain state, and outputs?
- How does Arbitrum make sure that the chain state and outputs are correct?
- How can Ethereum users and contracts interact with Arbitrum?
- How does Arbitrum support Ethereum-compatible contracts and transactions?
- How are ETH and tokens transferred into and out of Arbitrum chains, and how are they managed while on the chain?
- How can I run my own Arbitrum node or validator?
Optimistic Rollup
Arbitrum is an optimistic rollup. Let’s unpack that term.
Rollup
Arbitrum is a rollup, which means that the inputs to the chain -- the messages that are put into the inbox -- are all recorded on the Ethereum chain as calldata. Because of this, everyone has the information they would need to determine the current correct state of the chain -- they have the full history of the inbox, and the results are uniquely determined by the inbox history, so they can reconstruct the state of the chain based only on public information, if needed.
This also allows anyone to be a full participant in the Arbitrum protocol, to run an Arbitrum node or participate as a validator. Nothing about the history or state of the chain is a secret.
Optimistic
Arbitrum is optimistic, which means that Arbitrum advances the state of its chain by letting any party (a “validator”) post a rollup block that that party claims is correct, and then giving everyone else a chance to challenge that claim. If the challenge period (roughly a week) passes and nobody has challenged the claimed rollup block, Arbitrum confirms the rollup block as correct. If somebody challenges the claim during the challenge period, then Arbitrum uses an efficient dispute resolution protocol (detailed below) to identify which party is lying. The liar will forfeit a deposit, and the truth-teller will take part of that deposit as a reward for their efforts (some of the deposit is burned, guaranteeing that the liar is punished even if there's some collusion going on).
Because a party who tries to cheat will lose a deposit, attempts to cheat should be very rare, and the normal case will be a single party posting a correct rollup block, and nobody challenging it.
Interactive Proving
Among optimistic rollups, the most important design decision is how to resolve disputes. Suppose Alice claims that the chain will produce a certain result, and Bob disagrees. How will the protocol decide which version to accept?
There are basically two choices: interactive proving, or re-executing transactions. Arbitrum uses interactive proving, which we believe is more efficient and more flexible. Much of the design of Arbitrum follows from this fact.
Interactive proving
The idea of interactive proving is that Alice and Bob will engage in a back-and-forth protocol, refereed by an L1 contract, to resolve their dispute with minimal work required from any L1 contract.
Arbitrum's approach is based on dissection of the dispute. If Alice's claim covers N steps of execution, she posts two claims of size N/2 which combine to yield her initial N-step claim, then Bob picks one of Alice's N/2-step claims to challenge. Now the size of the dispute has been cut in half. This process continues, cutting the dispute in half at each stage, until they are disagreeing about a single step of execution. Note that so far the L1 referee hasn't had to think about execution "on the merits". It is only once the dispute is narrowed down to a single step that the L1 referee needs to resolve the dispute by looking at what the instruction actually does and whether Alice's claim about it is correct.
The key principle behind interactive proving is that if Alice and Bob are in a dispute, Alice and Bob should do as much off-chain work as possible needed to resolve their dispute, rather than putting that work onto an L1 contract.
Re-executing transactions
The alternative to interactive proving would be to have a rollup block contain a claimed machine state hash after every individual transaction. Then in case of a dispute, the L1 referee would emulate the execution of an entire transaction, to see whether the outcome matches Alice's claim.
Why interactive proving is better
We believe strongly that interactive proving is the superior approach, for the following reasons.
More efficient in the optimistic case: Because interactive proving can resolve disputes that are larger than one transaction, it can allow a rollup block to contain only a single claim about the end state of the chain after all of the execution covered by the block. By contrast, reexecution requires posting a state claim for each transaction within the rollup block. With hundred or thousands of transactions per rollup block, this is a substantial difference in L1 footprint -- and L1 footprint is the main component of cost.
More efficient in the pessimistic case: In case of a dispute, interactive proving requires the L1 referee contract only to check that Alice and Bob's actions "have the right shape", for example, that Alice has divided her N-step claim into two claims half as large. (The referee doesn't need to evaluate the correctness of Alice's claims--Bob does that, off-chain.) Only one instruction needs to be reexecuted. By contrast, reexecution requires the L1 referee to emulate the execution of an entire transaction.
Much higher per-tx gas limit: Interactive proving can escape from Ethereum's tight per-transaction gas limit; a transaction that requires so much gas it couldn't even fit into an Ethereum block is possible on Arbitrum. The gas limit isn't infinite, for obvious reasons, but it can be much larger than on Ethereum. As far as Ethereum is concerned, the only downside of a gas-heavy Arbitrum transaction is that it may require an interactive fraud proof with slightly more steps (and only if indeed it is fraudulent). By contrast, reexecution must impose a lower gas limit than Ethereum, because it must be possible to emulate execution of the transaction (which is more expensive than executing it directly) within a single Ethereum transaction.
No limit on contract size: Interactive proving does not need to create an Ethereum contract for each L2 contract, so it does not need contracts to fit within Ethereum's contract size limit. As far as Arbitrum's dispute contracts are concerned, deploying a contract on L2 is just another bit of computation like any other. By contrast, reexecution approaches must impose a lower contract size limit than Ethereum, because they need to be able to instrument a contract in order to emulate its execution, and the resulting instrumented code must fit into a single Ethereum contract.
More implementation flexibility: Interactive proving allows more flexibility in implementation, for example the ability to add instructions that don't exist in EVM. All that is necessary is the ability to verify a one-step proof on Ethereum. By contrast, reexecution approaches are tethered to limitations of the EVM.
Interactive proving drives the design of Arbitrum
Much of the design of Arbitrum is driven by the opportunities opened up by interactive proving. If you're reading about some feature of Arbitrum, and you're wondering why it exists, two good questions to ask are: "How does this support interactive proving?" and "How does this take advantage of interactive proving?" The answers to most "why questions" about Arbitrum relate to interactive proving.
Arbitrum Architecture
This diagram shows the basic architecture of Arbitrum.
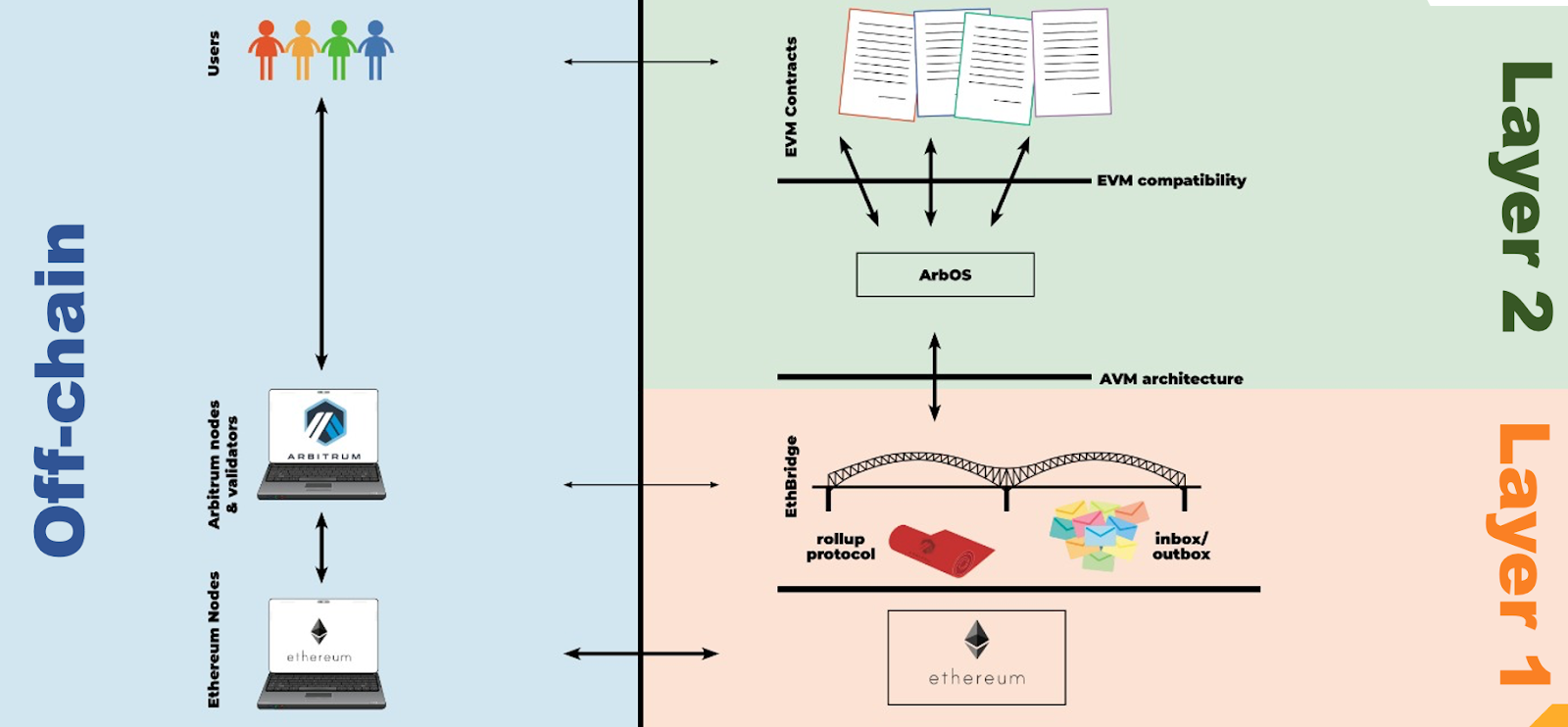
On the left we have users and the service providers who help them connect to the chain(s) of their choice. On the right we have the Arbitrum system itself, built in layers on top of Ethereum.
We’ll work our way up on the right side to describe how the Arbitrum stack works, then we’ll talk about what happens on the left side to connect users to it.
On the bottom right is good old Ethereum. Arbitrum builds on Ethereum and inherits its security from Ethereum.
On top of Ethereum is the EthBridge, a set of Ethereum contracts that manage an Arbitrum chain. The EthBridge referees the Arbitrum rollup protocol, which ensures that the layers above it operate correctly. (More on the rollup protocol below in the Rollup Protocol section.) The EthBridge also maintains the chain’s inbox and outbox, allowing people and contracts to send transaction messages to the chain, and to observe and use the outputs of those transactions. Users, L1 Ethereum contracts, and Arbitrum nodes make calls to the EthBridge contracts to interact with the Arbitrum chain.
The horizontal layer boundary above the EthBridge is labeled AVM Architecture, because what the EthBridge provides to the layer above it is an Arbitrum Virtual Machine, which can execute a computer program that reads inputs and produces outputs. This is the most important interface in Arbitrum, because it divides Layer 1 from Layer 2--it divides the Layer 1 components that provide the inbox/execution/outbox abstraction from the Layer 2 components that use that abstraction.
The next layer up is ArbOS. This is a software program, written by Offchain Labs, that runs on the Arbitrum Virtual Machine, and serves as a record-keeper, traffic cop, and enforcer for the execution of smart contracts on the Arbitrum chain. It’s called ArbOS because it plays a role like a (lightweight version of) the operating system on a laptop or phone--it’s the program that starts up first and that manages the execution of all other code on the chain. Importantly, ArbOS runs entirely at Layer 2, off of the Ethereum chain, so it can take advantage of the scalability and low cost of Layer 2 computation.
The horizontal layer boundary above ArbOS is called EVM compatibility because ArbOS provides an Ethereum Virtual Machine compatible execution environment for smart contracts. That is, you can send ArbOS the EVM code for a contract, in the same way you would send that contract to Ethereum, and ArbOS will load the contract and enable it to service transactions, just like on Ethereum. ArbOS takes care of the details of compatibility, so the smart contract programmer can just write their code like they would on Ethereum (or often, just take existing Ethereum contracts and redeploy them).
At the top of the stack--the upper right portion of the diagram--are EVM contracts which have been deployed to the Arbitrum chain by developers, and which execute transactions that are submitted to the chain.
That’s the right hand side of the diagram, which provides the Arbitrum chain functionality. Now let’s turn to the left side, which more directly supports users.
On the lower left are standard Ethereum nodes, which are used to interact with the Ethereum chain. Just above that are Arbitrum nodes. As the name suggests, these are used to interact with Arbitrum. They support the same API as Ethereum nodes, so they work well with existing Ethereum tools -- you can point your Ethereum-compatible wallet or tools at an Arbitrum node and they’ll be able to talk to each other. Just like on Ethereum, anyone can run an Arbitrum node, but many people will choose instead to rely on a node run by someone else.
Some Arbitrum nodes service user requests, and others choose to serve only as validators, which work to ensure the correctness of the Arbitrum chain. (See the Validators section for details.)
Last, but certainly not least, we see users on the upper left. Users use wallets, dapp front ends, and other tools to interact with Arbitrum. Because Arbitrum nodes support the same API as Ethereum, users don’t need entirely new tooling and developers don’t need to rewrite their dapps.
Above or Below the Line?
We often say that the key dividing line in the Arbitrum architecture is the AVM interface which divides Layer 1 from Layer 2. It can be useful to think about whether a particular activity is below the line or above the line.
Below the line functions are concerned with ensuring that the AVM, and therefore the chain, executes correctly. Above the line functions assume that the AVM will execute correctly, and focus on interacting with the software running at Layer 2.
As an example, Arbitrum validators operate below the line, because they participate in the rollup protocol, which is managed below-the-line by the EthBridge, to ensure that correct execution of the AVM is confirmed.
On the other hand, Arbitrum full nodes operate above the line, because they run a copy of the AVM locally, and assume that below-the-line mechanisms will ensure that the same result that they compute locally will eventually be confirmed by below-the-line mechanisms that they don’t monitor.
Most users, most of the time, will be thinking in above the line terms. They will be interacting with an Arbitrum chain as just another chain, without worrying about the below-the-line details that ensure that the chain won’t go wrong.
The EthBridge
The EthBridge is a set of Ethereum contracts that manage an Arbitrum chain. The EthBridge keeps track of the chain’s inbox contents, the hash of the chain’s state, and information about the outputs. The EthBridge is the ultimate source of authority about what is going on in the Arbitrum chain.
The EthBridge is the foundation that Arbitrum’s security is built on. The EthBridge runs on Ethereum, so it is transparent and executes trustlessly.
The Inbox contract manages the chain’s inbox. Inbox keeps track of the (hash of) every message in the inbox. Calling one of the send* methods of Inbox will insert a message into the Arbitrum chain’s inbox.
The Inbox contract makes sure that certain information in incoming messages is accurate: that the sender is correctly recorded, and that the Ethereum block number and timestamp are correctly recorded in the message.
Unsurprisingly, there is also an Outbox contract, which manages outputs of the chain; i.e., messages originating from Arbitrum about something that should (eventually) happen back on Ethereum (notably, withdrawals). When a rollup block is confirmed, the outputs produced in that rollup block are put into the outbox. How outputs end up being reflected on Ethereum is detailed in the Bridging section.
The Rollup contract and its friends are responsible for managing the rollup protocol. They track the state of the Arbitrum chain: the rollup blocks that have been proposed, accepted, and/or rejected, and who has staked on which rollup nodes. The Challenge contract and its friends are responsible for tracking and resolving any disputes between validators about which rollup blocks are correct. The functionality of Rollup, Challenge, and their friends will be detailed below in the Rollup Protocol section.
Arbitrum Rollup Protocol
Before diving into the rollup protocol, there are two things we need to cover.
First, if you’re an Arbitrum user or developer, you don’t need to understand the rollup protocol. You don’t ever need to think about it, unless you want to. Your relationship with it can be like a train passenger’s relationship with the train’s engine: you know it exists, you rely on it to keep working, but you don’t spend your time monitoring it or studying its internals.
You’re welcome to study, observe, and even participate in the rollup protocol, but you don’t need to, and most people won’t. So if you’re a typical train passenger who just wants to read or talk to your neighbor, you can skip right to the next section of this document. If not, read on!
The second thing to understand about the rollup protocol is that the protocol doesn’t decide the results of transactions, it only confirms the results. The results are uniquely determined by the sequence of messages in the chain’s inbox. So once your transaction message is in the chain’s inbox, its result is knowable--and Arbitrum nodes will report that your transaction is done. The role of the rollup protocol is to confirm transaction results that, as far as Arbitrum users are concerned, have already occurred. (This is why Arbitrum users can effectively ignore the rollup protocol.)
You might wonder why we need the rollup protocol. If everyone knows the results of transactions already, why bother confirming them? The protocol exists for two reasons. First, somebody might lie about a result, and we need a definitive, trustless way to tell who is lying. Second, Ethereum doesn’t know the results. The whole point of a Layer 2 scaling system is to run transactions without Ethereum needing to do all of the work--and indeed Arbitrum can go fast enough that Ethereum couldn’t hope to monitor every Arbitrum transaction. But once a result is confirmed, Ethereum knows about it and can rely on it.
With those preliminaries behind us, let’s jump into the details of the rollup protocol.
The parties who participate in the protocol are called validators. Anyone can be a validator. Some validators will choose to be stakers--they will place an ETH deposit which they’ll be able to recover if they’re not caught cheating. These roles are permissionless: anyone can be a validator or a staker.
The key security property of the rollup protocol is the AnyTrust Guarantee, which says that any one honest validator can force the correct execution of the chain to be confirmed. This means that execution of an Arbitrum chain is as trustless as Ethereum. You, and you alone (or someone you hire) can force your transactions to be processed correctly. And that is true no matter how many malicious people are trying to stop you.
The Rollup Chain
The rollup protocol tracks a chain of rollup blocks. These are separate from Ethereum blocks. You can think of the rollup blocks as forming a separate chain, which the Arbitrum rollup protocol manages and oversees.
Validators can propose rollup blocks. New rollup blocks will be unresolved at first. Eventually every rollup block will be resolved, by being either confirmed or rejected. The confirmed blocks make up the confirmed history of the chain.
Each rollup block contains:
- the rollup block number
- the predecessor block number: rollup block number of the last block before this one that is (claimed to be) correct
- the amount of computation the chain has done in its history (measured in ArbGas)
- the number of inbox messages have been consumed in the chain’s history
- a hash of the outputs produced over the chain’s history
- a hash of the AVM state.
Except for the rollup block number, the contents of the block are all just claims by the block’s proposer. Arbitrum doesn’t know at first whether any of these fields are correct. If all of these fields are correct, the protocol should eventually confirm the block. If one or more of these fields are incorrect, the protocol should eventually reject the block.
A block is implicitly claiming that its predecessor block is correct. This implies, transitively, that a block implicitly claims the correctness of a complete history of the chain: a sequence of ancestor blocks that reaches all the way back to the birth of the chain.
A block is also implicitly claiming that its older siblings (older blocks with the same predecessor), if there are any, are incorrect. If two blocks are siblings, and the older sibling is correct, then the younger sibling is considered incorrect, even if everything else in the younger sibling is true.
The block is assigned a deadline, which says how long other validators have to respond to it. If you’re a validator, and you agree that a rollup block is correct, you don’t need to do anything. If you disagree with a rollup block, you can post another block with a different result, and you’ll probably end up in a challenge against the first block’s staker. (More on challenges below.)
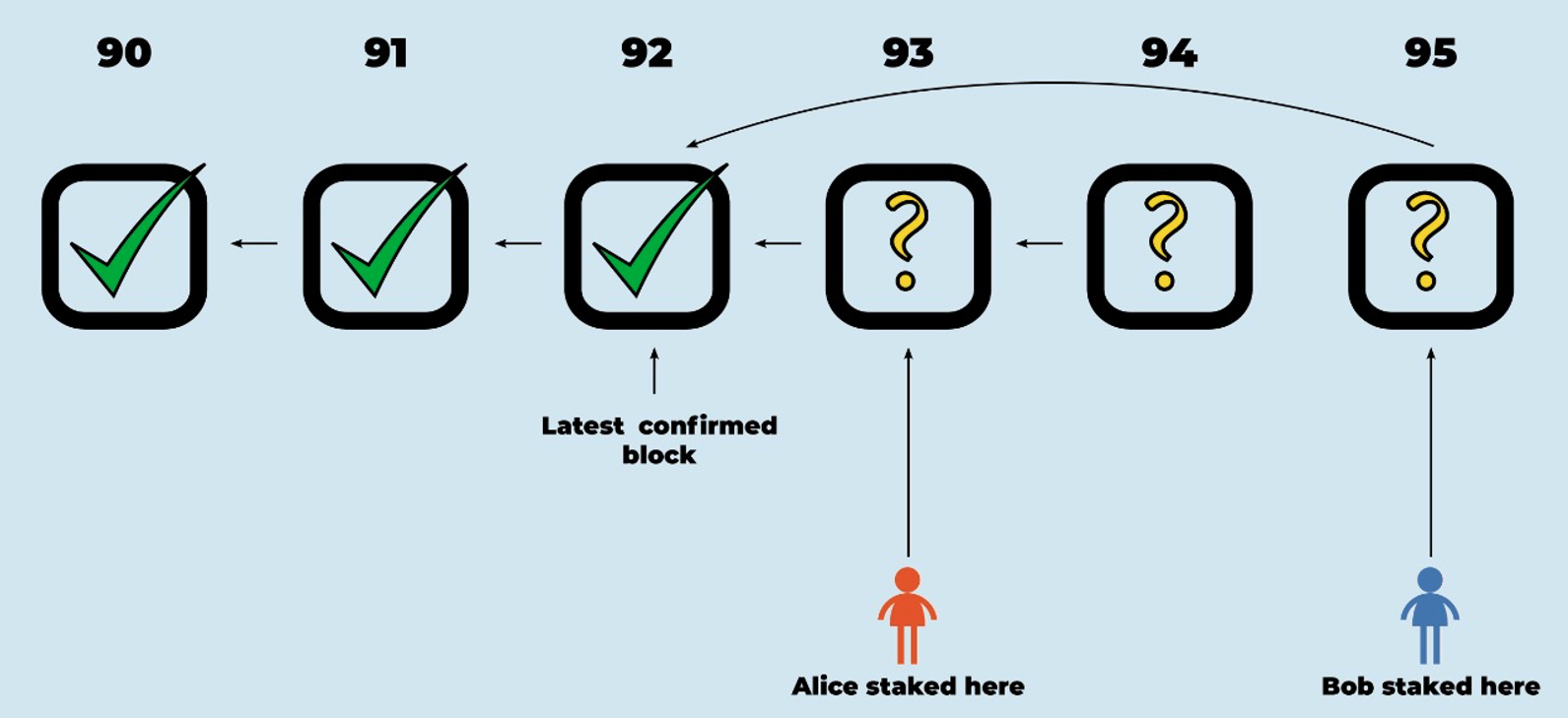
In the normal case, the rollup chain will look like this:
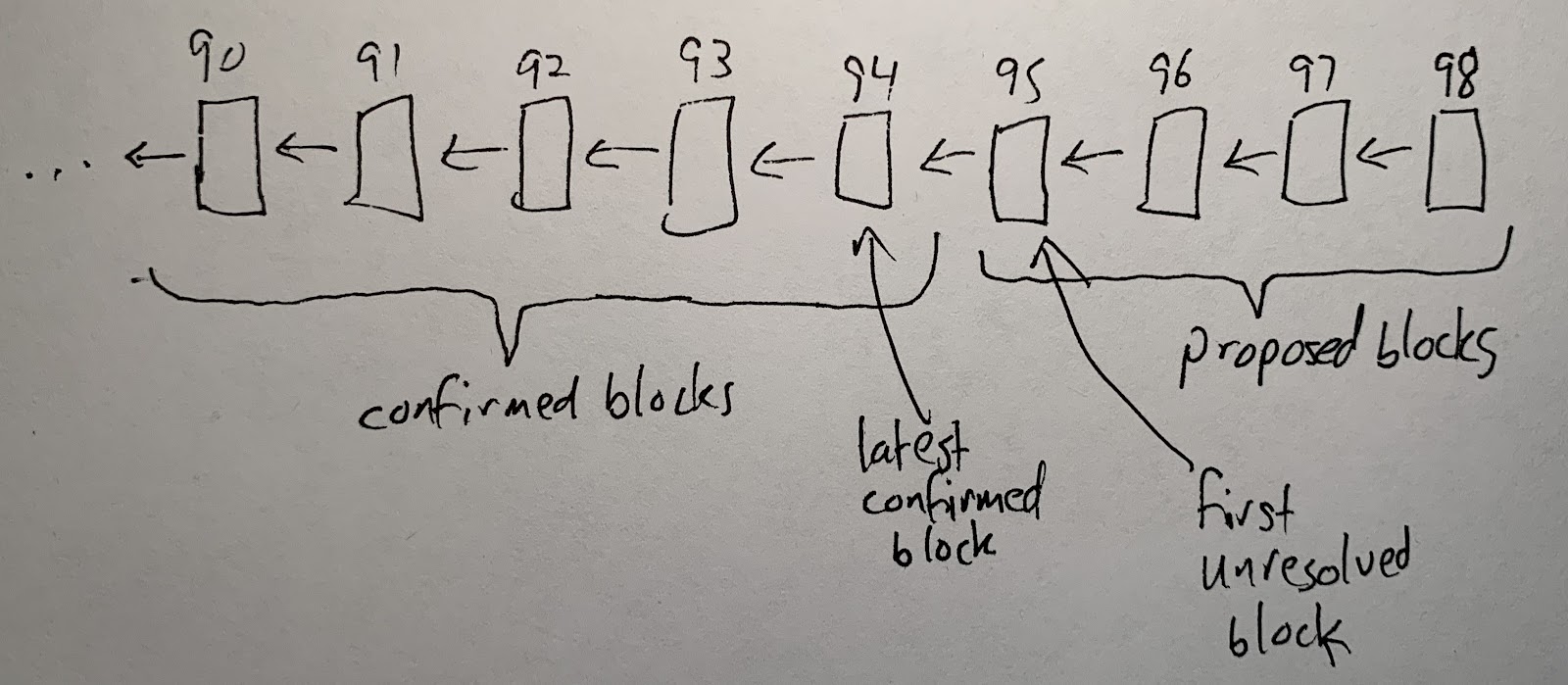
On the left, representing an earlier part of the chain’s history, we have confirmed rollup blocks. These have been fully accepted and recorded by the EthBridge. The newest of the confirmed blocks, block 94, is called the “latest confirmed block.” On the right, we see a set of newer proposed rollup blocks. The EthBridge can’t yet confirm or reject them, because their deadlines haven’t run out yet. The oldest block whose fate has yet to be determined, block 95, is called the “first unresolved block.”
Notice that a proposed block can build on an earlier proposed block. This allows validators to continue proposing blocks without needing to wait for the EthBridge to confirm the previous one. Normally, all of the proposed blocks will be valid, so they will all eventually be accepted.
Here’s another example of what the chain state might look like, if several validators are being malicious. It’s a contrived example, designed to illustrate a variety of cases that can come up in the protocol, all smashed into a single scenario.
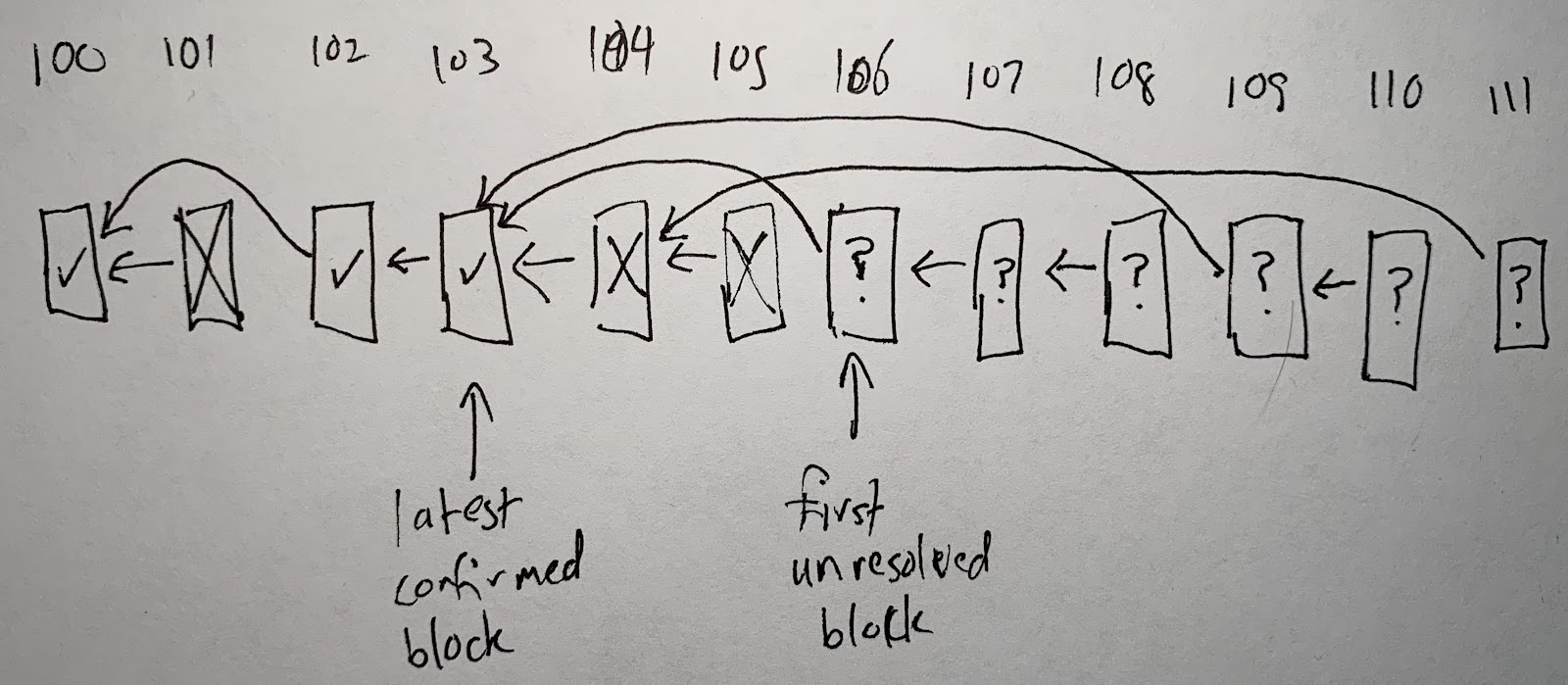
There’s a lot going on here, so let’s unpack it.
- Block 100 has been confirmed.
- Block 101 claimed to be a correct successor to block 100, but 101 was rejected (hence the X drawn in it).
- Block 102 was eventually confirmed as the correct successor to 100.
- Block 103 was confirmed and is now the latest confirmed block.
- Block 104 was proposed as a successor to block 103, and 105 was proposed as a successor to 104. 104 was rejected as incorrect, and as a consequence 105 was rejected because its predecessor was rejected.
- Block 106 is unresolved. It claims to be a correct successor to block 103 but the protocol hasn’t yet decided whether to confirm or reject it. It is the first unresolved block.
- Blocks 107 and 108 claim to chain from 106. They are also unresolved. If 106 is rejected, they will be automatically rejected too.
- Block 109 disagrees with block 106, because they both claim the same predecessor. At least one of them will eventually be rejected, but the protocol hasn’t yet resolved them.
- Block 110 claims to follow 109. It is unresolved. If 109 is rejected, 110 will be automatically rejected too.
- Block 111 claims to follow 105. 111 will inevitably be rejected because its predecessor has already been rejected. But it hasn’t been rejected yet, because the protocol resolves blocks in block number order, so the protocol will have to resolve 106 through 110, in order, before it can resolve 111. After 110 has been resolved, 111 can be rejected immediately.
Again: this sort of thing is very unlikely in practice. In this diagram, at least four parties must have staked on wrong rollup blocks, and when the dust settles at least four parties will have lost their stakes. The protocol handles these cases correctly, of course, but they’re rare corner cases. This diagram is designed to illustrate the variety of situations that are possible in principle, and how the protocol would deal with them.
Staking
At any given time, some validators will be stakers, and some will not. Stakers deposit funds that are held by the EthBridge and will be confiscated if the staker loses a challenge. Currently all chains accept stakes in ETH.
A single stake can cover a chain of rollup blocks. Every staker is staked on the latest confirmed block; and if you’re staked on a block, you can also stake on one successor of that block. So you might be staked on a sequence of blocks that represent a single coherent claim about the correct history of the chain. A single stake suffices to commit you to that sequence of blocks.
In order to create a new rollup block, you must be a staker, and you must already be staked on the predecessor of the new block you’re creating. The stake requirement for block creation ensures that anyone who creates a new block has something to lose if that block is eventually rejected.
The EthBridge keeps track of the current required stake amount. Normally this will equal the base stake amount, which is a parameter of the Arbitrum chain. But if the chain has been slow to make progress lately, the required stake will increase, as described in more detail below.
The rules for staking are as follows:
- If you’re not staked, you can stake on the latest confirmed rollup block. When doing this, you deposit with the EthBridge the current minimum stake amount.
- If you’re staked on a rollup block, you can also add your stake to any one successor of that block. (The EthBridge tracks the maximum rollup block number you’re staked on, and lets you add your stake to any successor of that block, updating your maximum to that successor.) This doesn’t require you to place a new stake.
- A special case of adding your stake to a successor block is when you create a new rollup block as a successor to a block you’re already staked on.
- If you’re staked only on the latest confirmed block (and possibly earlier blocks), you or anyone else can ask to have your stake refunded. Your staked funds will be returned to you, and you will no longer be a staker.
- If you lose a challenge, your stake is removed from all blocks and you forfeit your staked funds.
Notice that once you are staked on a rollup block, there is no way to unstake. You are committed to that block. Eventually one of two things will happen: that block will be confirmed, or you will lose your stake. The only way to get your stake back is to wait until all of the rollup blocks you are staked on are confirmed.
Setting the current minimum stake amount
One detail we deferred earlier is how the current minimum stake amount is set. Normally, this is just equal to the base stake amount, which is a parameter of the Arbitrum chain. However, if the chain has been slow to make progress in confirming blocks, the stake requirement will escalate temporarily. Specifically, the base stake amount is multiplied by a factor that is exponential in the time since the deadline of the first unresolved node passed. This ensures that if malicious parties are placing false stakes to try to delay progress (despite the fact that they’re losing those stakes), the stake requirement goes up so that the cost of such a delay attack increases exponentially. As block resolution starts advancing again, the stake requirement will go back down.
Rules for Confirming or Rejecting Rollup Blocks
The rules for resolving rollup blocks are fairly simple.
The first unresolved block can be confirmed if:
- the block’s predecessor is the latest confirmed block, and
- the block’s deadline has passed, and
- there is at least one staker, and
- all stakers are staked on the block.
The first unresolved block can be rejected if:
- the block’s predecessor has been rejected, or
- all of the following are true:
- the block’s deadline has passed, and
- there is at least one staker, and
- no staker is staked on the block.
A consequence of these rules is that once the first unresolved block’s deadline has passed (and assuming there is at least one staker staked on something other than the latest confirmed block), the only way the block can be unresolvable is if at least one staker is staked on it and at least one staker is staked on a different block with the same predecessor. If this happens, the two stakers are disagreeing about which block is correct. It’s time for a challenge, to resolve the disagreement.
Challenges
Suppose the rollup chain looks like this:
Blocks 93 and 95 are sibling blocks (they both have 92 as predecessor). Alice is staked on 93 and Bob is staked on 95.
At this point we know that Alice and Bob disagree about the correctness of block 93, with Alice committed to 93 being correct and Bob committed to 93 being incorrect. (Bob is staked on 95, and 95 claims that 92 is the last correct block before it, which implies that 93 would be incorrect.)
Whenever two stakers are staked on sibling blocks, and neither of those stakers is already in a challenge, anyone can start a challenge between the two. The rollup protocol will record the challenge and referee it, eventually declaring a winner and confiscating the loser’s stake. The loser will be removed as a staker.
The challenge is a game in which Alice and Bob alternate moves, with an Ethereum contract as the referee. Alice, the defender, moves first.
The game will operate in two phases: dissection, followed by one-step proof. Dissection will narrow down the size of the dispute until it is a dispute about just one instruction of execution. Then the one-step proof will determine who is right about that one instruction.
We’ll describe the dissection part of the protocol twice. First, we’ll give a simplified version which is easier to understand but less efficient. Then we’ll describe how the real version differs from the simplified one.
Dissection Protocol: Simplified Version
Alice is defending the claim that starting with the state in the predecessor block, the state of the Virtual Machine can advance to the state specified in block A. Essentially she is claiming that the Virtual Machine can execute N instructions, and that that execution will consume M inbox messages and transform the hash of outputs from H’ to H.
Alice’s first move requires her to dissect her claims about intermediate states between the beginning (0 instructions executed) and the end (N instructions executed). So we require Alice to divide her claim in half, and post the state at the half-way point, after N/2 instructions have been executed.
Now Alice has effectively bisected her N-step assertion into two (N/2)-step assertions. Bob has to point to one of those two half-size assertions and claim it is wrong.
At this point we’re effectively back in the original situation: Alice having made an assertion that Bob disagrees with. But we have cut the size of the assertion in half, from N to N/2. We can apply the same method again, with Alice bisecting and Bob choosing one of the halves, to reduce the size to N/4. And we can continue bisecting, so that after a logarithmic number of rounds Alice and Bob will be disagreeing about a single step of execution. That’s where the dissection phase of the protocol ends, and Alice must make a one-step proof which will be checked by the EthBridge.
Why Dissection Correctly Identifies a Cheater
Before talking about the complexities of the real challenge protocol, let’s stop to understand why the simplified version of the protocol is correct. Here correctness means two things: (1) if Alice’s initial claim is correct, Alice can always win the challenge, and (2) if Alice’s initial claim is incorrect, Bob can always win the challenge.
To prove (1), observe that if Alice’s initial claim is correct, she can offer a truthful midpoint claim, and both of the implied half-size claims will be correct. So whichever half Bob objects to, Alice will again be in the position of defending a correct claim. At each stage of the protocol, Alice will be defending a correct claim. At the end, Alice will have a correct one-step claim to prove, so that claim will be provable and Alice can win the challenge.
To prove (2), observe that if Alice’s initial claim is incorrect, this can only be because her claimed endpoint after N steps is incorrect. Now when Alice offers her midpoint state claim, that midpoint claim is either correct or incorrect. If it’s incorrect, then Bob can challenge Alice’s first-half claim, which will be incorrect. If Alice’s midpoint state claim is correct, then her second-half claim must be incorrect, so Bob can challenge that. So whatever Alice does, Bob will be able to challenge an incorrect half-size claim. At each stage of the protocol, Bob can identify an incorrect claim to challenge. At the end, Alice will have an incorrect one-step claim to prove, which she will be unable to do, so Bob can win the challenge.
(If you’re a stickler for mathematical precision, it should be clear how these arguments can be turned into proofs by induction on N.)
The Real Dissection Protocol
The real dissection protocol is conceptually similar to the simplified one described above, but with several changes that improve efficiency or deal with necessary corner cases. Here is a list of the differences.
K-way dissection: Rather than dividing a claim into two segments of size N/2, we divide it into K segments of size N/K. This requires posting K-1 intermediate claims, at points evenly spaced through the claimed execution. This reduces the number of rounds by a factor of log(K)/log(2).
Answer a dissection with a dissection: Rather than having each round of the protocol require two moves, where Alice dissects and Bob chooses a segment to challenge, we instead require Bob, in challenging a segment, to post his own claimed endpoint state for that segment (which must differ from Alice’s) as well as his own dissection of his version of the segment. Alice will then respond by identifying a subsegment, posting an alternative endpoint for that segment, and dissecting it. This reduces the number of moves in the game by an additional factor of 2, because the size is cut by a factor of K for every move, rather than for every two moves.
Dissect by ArbGas, Not By Steps: Rather than measuring the size of an interval by the number of instructions executed, we measure by the amount of ArbGas it consumes. This allows the protocol to precisely determine how long it will take a validator to check the correctness of a claim (because validator checking time is proportional to ArbGas used) which allows the protocol to more precisely set deadlines for rollup nodes. The drawback of this is that different instructions require different amounts of ArbGas, so we can no longer assume that a segment of execution can end on an exact N/K step boundary. The real protocol allows a claim to end at the first instruction boundary at or after its target endpoint; and the correctness argument accounts for the possibility that parties will lie about where the correct endpoint of a segment is.
Deal With the Empty-Inbox Case: The real AVM can’t always execute N ArbGas units without getting stuck. The machine might halt, or it might have to wait because its inbox is exhausted so it can’t go on until more messages arrive. So Bob must be allowed to respond to Alice’s claim of N units of execution by claiming that N steps are not possible. The real protocol thus allows any response (but not the initial claim) to claim a special end state that means essentially that the specified amount of execution is not possible under the current conditions.
Time Limits: Each player is given a time allowance. The total time a player uses for all of their moves must be less than the time allowance, or they lose the game. Think of the time allowance as being about a week.
It should be clear that these changes don’t affect the basic correctness of the challenge protocol. They do, however, improve its efficiency and enable it to handle all of the cases that can come up in practice.
Efficiency
The challenge protocol is designed so that the dispute can be resolved with a minimum of work required by the EthBridge in its role as referee. When it is Alice’s move, the EthBridge only needs to keep track of the time Alice uses, and ensure that her move does include K-1 intermediate points as required. The EthBridge doesn’t need to pay attention to whether those claims are correct in any way; it only needs to know whether Alice’s move “has the right shape”.
The only point where the EthBridge needs to evaluate a move “on the merits” is at the one-step proof, where it needs to look at Alice’s proof and determine whether the proof that was provided does indeed establish that the virtual machine moves from the before state to the claimed after state after one step of computation. We’ll discuss the details of one-step proofs below in the Arbitrum Virtual Machine section.
Validators
Some Arbitrum nodes will choose to act as validators. This means that they watch the progress of the rollup protocol and participate in that protocol to advance the state of the chain securely.
Not all nodes will choose to do this. Because the rollup protocol doesn’t decide what the chain will do but merely confirms the correct behavior that is fully determined by the inbox messages, a node can ignore the rollup protocol and simply compute for itself the correct behavior. For more on what such nodes might do, see the Full Nodes section.
Being a validator is permissionless--anyone can do it. Offchain Labs provides open source validator software, including a pre-built Docker image.
Every validator can choose their own approach, but we expect validators to follow three common strategies.
- The active validator strategy tries to advance the state of the chain by proposing new rollup blocks. An active validator is always staked, because creating a rollup block requires being staked. A chain really only needs one honest active validator; any more is an inefficient use of resources. For the Arbitrum One chain, Offchain Labs runs an active validator.
- The defensive validator strategy watches the rollup protocol operate. If only correct rollup blocks are proposed, this strategy doesn't stake. But if an incorrect block is proposed, this strategy intervenes by posting a correct block or staking on a correct block that another party has posted. This strategy avoids staking when things are going well, but if someone is dishonest it stakes in order to defend the correct outcome.
- The watchtower validator strategy never stakes. It simply watches the rollup protocol and if an incorrect block is proposed, it raises the alarm (by whatever means it chooses) so that others can intervene. This strategy assumes that other parties who are willing to stake will be willing to intervene in order to take some of the dishonest proposer’s stake, and that that can happen before the dishonest block’s deadline expires. (In practice this will allow several days for a response.)
Under normal conditions, validators using the defensive and watchtower strategies won’t do anything except observe. A malicious actor who is considering whether to try cheating won’t be able to tell how many defensive and watchtower validators are operating incognito. Perhaps some defensive validators will announce themselves, but others probably won’t, so a would-be attacker will always have to worry that defenders are waiting to emerge.
Who will be validators? Anyone can do it, but most people will choose not to. In practice we expect people to validate a chain for several reasons.
- Some validators will be paid, by the party that created the chain or someone else. On the Arbitrum One chain, Offchain Labs will hire some validators.
- Parties who have significant assets at stake on a chain, such as dapp developers, exchanges, power-users, and liquidity providers, may choose to validate in order to protect their investment.
- Anyone who chooses to validate can do so. Some users will probably choose to validate in order to protect their own interests or just to be good citizens. But ordinary users don’t need to validate, and we expect that the vast majority of users won’t.
AVM: The Arbitrum Virtual Machine
The Arbitrum Virtual Machine (AVM) is the interface between the Layer 1 and Layer 2 parts of Arbitrum. Layer 1 provides the AVM interface and ensures correct execution of the virtual machine. Layer 2 runs on the AVM virtual machine and provides the functionality to deploy and run contracts, track balances, and all of the things a smart-contract-enabled blockchain needs to do.
Every Arbitrum chain has a single AVM which does all of the computation and maintains all of the storage for everything that happens on the chain. Unlike some other systems which have a separate “VM” for each contract, Arbitrum uses a single virtual machine for the whole chain, much like Ethereum. The management of multiple contracts on an Arbitrum chain is done by software that runs on top of the AVM.
At its core, a chain’s VM executes in this simple model, consuming messages from its inbox, changing its state, and producing outputs.
The starting point for the AVM design is the Ethereum Virtual Machine (EVM). Because Arbitrum aims to efficiently execute programs written or compiled for EVM, the AVM uses many aspects of EVM unchanged. For example, AVM adopts EVM's basic integer datatype (a 256-bit big-endian unsigned integer), as well as the instructions that operate on EVM integers.
Why AVM differs from EVM
Differences between AVM and EVM are motivated by the needs of Arbitrum's Layer 2 protocol and Arbitrum's use of a interactive proving to resolve disputes.
Execution vs. proving
Arbitrum, unlike EVM and similar architectures, supports both execution (advancing the state of a computation by executing it, which is always done off-chain in Arbitrum) and proving (convincing an L1 contract or other trusted party that a claim about execution is correct). EVM-based systems resolve disputes by re-executing the disputed code, whereas Arbitrum relies on a more efficient challenge protocol that leads to an eventual proof.
One nice consequence of separating execution from proving -- and never needing to re-execute blocks of code on an L1 chain -- is that we can optimize execution and proving for the different environments they’ll be used in. Execution is optimized for speed in a local, trusted environment, because local execution is the common case. Proving, on the other hand, will be needed less often but must still be efficient enough to be viable even on the busy Ethereum L1 chain. Proof-checking will rarely be needed, but proving must always be possible. The logical separation of execution from proving allows execution speed to be optimized more aggressively in the common case where proving turns out not to be needed.
Requirements from ArbOS
Another difference in requirements is that Arbitrum uses ArbOS, an "operating system" that runs at Layer 2. ArbOS controls the execution of separate contracts to isolate them from each other and track their resource usage. In support of this, the AVM includes instructions to support saving and restoring the machine's stack, managing machine registers that track resource usage, and receiving messages from external callers. These instructions are used by ArbOS itself, but ArbOS ensures that they will never appear in untrusted code.
Supporting these functions in Layer 2 trusted software, rather than building them in to the L1-enforced rules of the architecture as Ethereum does, offers significant advantages in cost because these operations can benefit from the lower cost of computation and storage at Layer 2, instead of having to manage those resources as part of the Layer 1 EthBridge contract. Having a trusted operating system at Layer 2 also has significant advantages in flexibility, because Layer 2 code is easier to evolve, or to customize for a particular chain, than a Layer-1 enforced VM architecture would be.
The use of a Layer 2 trusted operating system does require some support in the virtual machine instruction set, for example to allow the OS to limit and track resource usage by contracts.
Supporting Merkleization
Any Layer 2 protocol that relies on assertions and dispute resolution must define a rule for Merkle-hashing the full state of the virtual machine so that claims about parts of the state can be efficiently made to the base layer. That rule must be part of the architecture specification because it is relied upon in resolving disputes. It must also be reasonably efficient for validators to maintain the Merkle hash and/or recompute it when needed. This affects how the architecture structures its memory, for example. Any storage structure that is large and mutable will be relatively expensive to Merkleize, and a specific algorithm for Merkleizing it would need to be part of the architecture specification.
The AVM architecture responds to this challenge by having only bounded-size, immutable memory objects ("Tuples"), which can include other Tuples by reference. Tuples cannot be modified in-place but there is an instruction to copy a Tuple with a modification. This allows the construction of tree structures which can behave like a large flat memory. Applications can use functionalities such as large flat arrays, key-value stores, and so on, by accessing libraries that use Tuples internally.
The semantics of Tuples make it impossible to create cyclic structures of Tuples, so an AVM implementation can safely manage Tuples by using reference-counted, immutable structures. The hash of each Tuple value need only be computed once, because the contents are immutable.
Codepoints: Optimizing code for proving
The conventional organization of code is to store a linear array of instructions, and keep a program counter pointing to the next instruction that will be executed. With this conventional approach, proving the result of one instruction of execution requires logarithmic time and space, because a Merkle proof must be presented to prove which instruction is at the current program counter.
The AVM does this more efficiently, by separating execution from proving. Execution uses the standard abstraction of an array of instructions indexed by a program counter, but proving uses an equivalent CodePoint construct that allows proving and proof-checking to be done in constant time and space. The CodePoint for the instruction at some PC value is the pair (opcode at PC, Hash(CodePoint at PC+1)). (If there is no CodePoint at PC+1, then zero is used instead.)
For proving purposes, the "program counter" is replaced by a "current CodePoint hash" value, which is part of the machine state. The preimage of this hash will contain the current opcode, and the hash of the following codepoint, which is everything a proof verifier needs to verify what the opcode is and what the current CodePoint hash value will be after the instruction, if the instruction isn't a Jump.
All jump instructions use jump destinations that are CodePoints, so a proof about execution of a jump instruction also has immediately at hand not only the PC that is being jumped to, but also what the contents of the "current CodePoint hash" register will be after the jump executes. In every case, proof and verification requires constant time and space.
In normal execution (when proving is not required), implementations will typically just use PC values as on a conventional architecture. However, when a one-step proof is needed, the prover can use a pre-built lookup table to get the CodePoint hashes corresponding to any relevant PCs.
Creating code at runtime
Code is added to an AVM in two ways. First, some code is created when the AVM starts running. This code is read in from an AVM executable file (a .mexe file) and preloaded by the AVM emulator.
Second, the AVM has three instructions to create new CodePoints: one that makes a new Error CodePoint, and two that make new CodePoints (one for a CodePoint with an immediate value and one for a CodePoint without) given an opcode, possibly an immediate value, and a next CodePoint. These are used by ArbOS when translating EVM code for execution. (For more details on this, see the ArbOS section.)
Getting messages from the Inbox
The inbox instruction consumes the next message from the VM’s inbox and pushes it onto the AVM's Stack. If all messages in the inbox have been consumed already, the inbox instruction blocks--the VM cannot complete the inbox instruction, nor can it do anything else, until a message arrives and the inbox instruction can complete. If the inbox has been completely consumed, any purported one-step proof of executing the inbox instruction will be rejected.
Producing outputs
The AVM has two instructions that can produce outputs: send and log. Both are hashed into the output hash accumulator that records the (hash of) the VM’s outputs, but send causes its value to be recorded as calldata on the L1 chain, while log does not. This means that outputs produced with send will be visible to L1 contracts, while those produced with log will not. Of course, sends are more expensive than logs. A useful design pattern is for a sequence of values to be produced as logs, and then a Merkle hash of those values to be produced as a single send. That allows an L1 contract to see the Merkle hash of the full sequence of outputs, so that it can verify the individual values when it sees them. ArbOS uses this design pattern, as described below.
ArbGas and gas tracking
The AVM has a notion of AVM gas, which is like gas on Ethereum. AVM gas measures the cost of executing an instruction, based on how long it will take a validator to execute it. Every AVM instruction has an AVM gas cost.
Arbitrum instructions have different gas costs than their Ethereum counterparts, for two reasons. First, the relative costs of executing Instruction A versus Instruction B can be different on a Layer 2 system versus on Ethereum. For example, storage accesses can be cheaper on Arbitrum relative to add instructions. AVM gas costs are based on the relative cost on Arbitrum.
The AVM architecture has a machine register called AVM Gas Remaining. Before executing any instruction, the AVM gas cost of that instruction is deducted from AVM Gas Remaining. If this would underflow the register (indicating that the execution is “out of AVM gas”) a hard error is generated and the AVM Gas Remaining register is set to MaxUint256.
The AVM has instructions to get and set the AVM Gas Remaining register, which ArbOS uses to limit and count the AVM gas used by user contracts.
(For usability reasons, the Arbitrum API exposes "ArbGas" rather than "AVM gas", where 1 ArbGas is defined to be equal to 100 AVM gas. This makes gas amounts and gas prices more intuitive and more consistent with legacy user interfaces from tools like wallets.)
For information on ArbGas prices and other fee-related matters, see the Fees section.
Error handling
Error conditions can arise in AVM execution in several ways, including stack underflows, AVM gas exhaustion, and type errors such as trying to jump to a value that is not a CodePoint.
The AVM architecture has an Error CodePoint register that can be read and written by special instructions. When an error occurs, the Next CodePoint register is set equal to the Error CodePoint register, essentially jumping to the specified error handler.
ArbOS
ArbOS is a trusted "operating system” at Layer 2 that isolates untrusted contracts from each other, tracks and limits their resource usage, and manages the economic model that collects fees from users to fund the operation of a chain. When an Arbitrum chain is started, ArbOS is pre-loaded into the chain’s AVM instance, and ready to run. After some initialization work, ArbOS sits in its main run loop, reading a message from the inbox, doing work based on that message including possibly producing outputs, then circling back to get the next message.
Why ArbOS?
In Arbitrum, much of the work that would otherwise have to be done expensively at Layer 1 is instead done by ArbOS, trustlessly performing these functions at the speed and low cost of Layer 2.
Supporting these functions in Layer 2 trusted software, rather than building them in to the L1-enforced rules of the architecture as Ethereum does, offers significant advantages in cost because these operations can benefit from the lower cost of computation and storage at Layer 2, instead of having to manage those resources as part of the Layer 1 EthBridge contract. Having a trusted operating system at Layer 2 also has significant advantages in flexibility, because Layer 2 code is easier to evolve, or to customize for a particular chain, than a Layer-1 enforced VM architecture would be.
The use of a Layer 2 trusted operating system does require some support in the architecture, for example to allow the OS to limit and track resource usage by contracts. The AVM architecture provides that support.
For a detailed specification describing the format of messages used for communication between clients, the EthBridge, and ArbOS, see the ArbOS Message Formats Specification.
EVM Compatibility
ArbOS provides functionality to emulate the execution of an Ethereum-compatible chain. It tracks accounts, executes contract code, and handles the details of creating and running EVM code. Clients can submit EVM transactions, including the ones that deploy contracts, and ArbOS ensures that the submitted transactions run in a compatible manner.
The account table
ArbOS maintains an account table, which keeps track of the state of every account in the emulated Ethereum chain. The table entry for an account contains the account’s balance, its nonce, its code and storage (if it is a contract), and some other information associated with Arbitrum-specific features. An account’s entry in the table is initialized the first time anything happens in the account on the Arbitrum chain.
Translating EVM code to run on AVM
EVM code can’t run directly on the AVM architecture, so ArbOS has to translate EVM code into equivalent AVM code in order to run it. This is done within ArbOS to ensure that it is trustless.
(Some old versions of Arbitrum used a separate compiler to translate EVM to AVM code, but that had significant disadvantages in both security and functionality, so we switched to built-in translation in ArbOS.)
ArbOS takes an EVM contract’s program and translates it into an AVM code segment that has equivalent functionality. Some instructions can be translated directly; for example an EVM add instruction translates into a single AVM add instruction. Other instructions translate into a call to a library provided by ArbOS. For example, the EVM CREATE2 instruction, which creates a new contract whose address is computed in a special way, translates into a call to an ArbOS function called evmOp_create2.
To deploy a new contract, ArbOS takes the submitted EVM constructor code, translates it into AVM code for the constructor, and runs that code. If it completes successfully, ArbOS takes the return data, interprets it as EVM code, translates that into AVM code, and then installs that AVM code into the account table as the code for the now-deployed contract. Future calls to the contract will jump to the beginning of that AVM code.
More EVM emulation details
When an EVM transaction is running, ArbOS keeps an EVM Call Stack, a stack of EVM Call Frames which represent the nested calls inside of the transaction. Each EVM Call Frame records the data for one level of call. When an inner call returns or reverts, ArbOS cleans up its call frame, and either propagates the effects of the call (if the call returned) or discards them (if the call reverted).
The EVM call family of instructions (call, delegatecall, etc.) invoke ArbOS library functions that create new EVM Call Frames according to the EVM-specified behavior of the call type that was made, including propagation of calldata and gas. Any gas left over after a call is returned to the caller, as on Ethereum.
Certain errors in executing EVM, such as stack underflows, will trigger a corresponding error during AVM emulation. ArbOS’s error handler detects that the error occurred while emulating a certain EVM call, and reverts that call accordingly, returning control to its caller or providing a transaction receipt as appropriate. ArbOS distinguishes out-of-gas errors from other errors by looking at the AVM Gas Remaining register, which is automatically set to MaxUint256 if an out-of-gas error occurred.
The result of these mechanisms is that EVM code can run compatibly on Arbitrum.
There are three main differences between EVM execution on Arbitrum compared to Ethereum.
First, the two EVM instructions DIFFICULTY and COINBASE, which don’t make sense on an L2 chain, return fixed constant values.
Second, the EVM instruction BLOCKHASH returns a pseudorandom value that is a digest of the chain’s history, but not the same hash value that Ethereum would return at the same block number.
Third, Arbitrum uses the ArbGas system so everything related to gas is denominated in ArbGas, including the gas costs of operations, and the results of gas-related instructions like GASLIMIT and GASPRICE.
Deploying EVM contracts
On Ethereum, an EVM contract is deployed by sending a transaction to the null account, with calldata consisting of the contract’s constructor. Ethereum runs the constructor, and if the constructor succeeds, its return data is set up as the code for the new contract.
Arbitrum uses a similar pattern. To deploy a new EVM contract, ArbOS takes the submitted EVM constructor code, translates it into AVM code for the constructor, and runs that AVM code. If it completes successfully, ArbOS takes the return data, interprets it as EVM code, translates that into AVM code, and then installs that AVM code into the account table as the code for the now-deployed contract. Future calls to the contract will jump to the beginning of that AVM code.
Transaction receipts
When an EVM transaction finishes running, whether or not it succeeded, ArbOS issues a transaction receipt, using the AVM log instruction. The receipt is detected by Arbitrum nodes, which can use it to provide results to users according to the standard Ethereum RPC API.
Full Nodes
As the name suggests, full nodes in Arbitrum play the same role that full nodes play in Ethereum: they know the state of the chain and they provide an API that others can use to interact with the chain.
Arbitrum full nodes operate "above the line", meaning that they don’t worry about the rollup protocol but simply treat their Arbitrum chain as a machine consuming inputs to produce outputs. A full node has a built-in AVM emulator that allows it to do this.
Batching transactions: full node as an aggregator
One important role of a full node is serving as an aggregator, which means that the full node receives a set of signed transactions from users and assembles them into a batch which it submits to the chain’s inbox as a single unit. Submitting transactions in batches is more efficient than one-by-one submission, because each submission is an L1 transaction to the EthBridge, and Ethereum imposes a base cost of 21,000 L1 gas per transaction. Submitting a batch allows that fixed cost (and some other fixed costs) to be amortized across a larger group of user transactions. That said, submitting a batch is permissionless, so any user can, say, submit a single transaction "batch" if the need arises; Arbitrum thereby inherits the same censorship resistance as the Ethereum.
Compressing transactions
In addition to batching transactions, full nodes can also compress transactions to save on L1 calldata space. Compression is transparent to users and to contracts running on Arbitrum--they see only normal uncompressed transactions. The process works like this: the user submits a normal transaction to a full node; the full node compresses the transactions and submits it to the chain; ArbOS receives the transaction and uncompresses it to recover the original transaction; ArbOS verifies the signature on the transaction and processes the transaction.
Compression can make the “header information” in a transaction much smaller. Full nodes typically use both compression and batching when submitting transactions.
Aggregator costs and fees
An aggregator that submits transactions on behalf of users will have costs due to the L1 transactions it uses to submit those transactions to the Inbox contract. Arbitrum includes a facility to collect fees from users, to reimburse the aggregator for its costs. This is detailed in the ArbGas and Fees section.
Sequencer Mode
Sequencer mode is an optional feature of Arbitrum chains, which can be turned on or off for each chain. We expect it to be enabled for most chains. Arbitrum One uses a sequencer that is operated by Offchain Labs.
The sequencer is a specially designated full node, which is given limited power to control the ordering of transactions. This allows the sequencer to guarantee the results of user transactions immediately, without needing to wait for anything to happen on Ethereum. So no need to wait five minutes or so for block confirmations--and no need to even wait 15 seconds for Ethereum to make a block.
Clients interact with the sequencer in exactly the same way they would interact with any full node, for example by giving their wallet software a network URL that happens to point to the sequencer.
Instant confirmation
Without a sequencer, a node can predict what the results of a client transaction will be, but the node can't be sure, because it can't know or control how the transactions it submits will be ordered in the inbox, relative to transactions submitted by other nodes.
The sequencer is given more control over ordering, so it has the power to assign its clients' transactions a position in the inbox queue, thereby ensuring that it can determine the results of client transactions immediately. The sequencer's power to reorder has limits (see below for details) but it does have more power than anyone else to influence transaction ordering.
Inboxes, fast and slow
When we add a sequencer, the operation of the inbox changes.
- Only the sequencer can put new messages directly into the inbox. The sequencer tags the messages it is submitting with an Ethereum block number and timestamp. (ArbOS ensures that these are non-decreasing, adjusting them upward if necessary to avoid decreases.)
- Anyone else can submit a message, but messages submitted by non-sequencer nodes will be put into the "delayed inbox" queue, which is managed by an L1 Ethereum contract.
- Messages in the delayed inbox queue will wait there until the sequencer chooses to "release" them into the main inbox, where they will be added to the end of the inbox. A well-behaved sequencer will typically release delayed messages after about ten minutes, for reasons explained below.
- Alternatively, if a message has been in the delayed inbox queue for longer than a maximum delay interval (currently 24 hours) then anyone can force it to be promoted into the main inbox. (This ensures that the sequencer can only delay messages but can't censor them.)
If the sequencer is well-behaved...
A well-behaved sequencer will accept transactions from all requesters and treat them fairly, giving each one a promised transaction result as quickly as it can.
It will also minimize the delay it imposes on non-sequencer transactions by releasing delayed messages promptly, consistent with the goal of providing strong promises of transaction results. Specifically, if the sequencer believes that 40 confirmation blocks are needed to have good confidence of finality on Ethereum, then it will release delayed messages after 40 blocks. This is enough to ensure that the sequencer knows exactly which transactions will precede its current transaction, because those preceding transactions have finality. There is no need for a benign sequencer to delay non-sequencer messages more than that, so it won't.
This does mean that transactions that go through the delayed inbox will take longer to get finality. Their time to finality will roughly double, because they will have to wait one finality period for promotion, then another finality period for the Ethereum transaction that promoted them to achieve finality.
This is the basic tradeoff of having a sequencer: if your message uses the sequencer, finality is C blocks faster; but if your message doesn't use the sequencer, finality is C blocks slower. This is usually a good tradeoff, because most transactions will use the sequencer; and because the practical difference between instant and 10-minute finality is bigger than the difference between 10-minute and 20-minute finality.
So a sequencer is generally a win, if the sequencer is well behaved.
If the sequencer is malicious...
A malicious sequencer, on the other hand, could cause some pain. If it refuses to handle your transactions, you're forced to go through the delayed inbox, with longer delay. And a malicious sequencer has great power to front-run everyone's transactions, so it could profit greatly at users' expense.
On Arbitrum One, Offchain Labs runs a sequencer which is well-behaved--we promise!. This will be useful but it's not decentralized. Over time, we'll switch to decentralized, fair sequencing, as described below.
Because the sequencer will be run by a trusted party at first, and will be decentralized later, we haven't built in a mechanism to directly punish a misbehaving sequencer. We're asking users to trust the centralized sequencer at first, until we switch to decentralized fair sequencing later.
Decentralized fair sequencing
Viewed from 30,000 feet, decentralized fair sequencing isn't too complicated. Instead of being a single centralized server, the sequencer is a committee of servers, and as long as a large enough supermajority of the committee is honest, the sequencer will establish a fair ordering over transactions.
How to achieve this is more complicated. Research by a team at Cornell Tech, including Offchain Labs CEO and Co-founder Steven Goldfeder, developed the first-ever decentralized fair sequencing algorithm. With some improvements that are under development, these concepts will form the basis for our longer-term solution, of a fair decentralized sequencer.
Bridging
We have already covered how users interact with L2 contracts--they submit transactions by putting messages into the chain’s inbox, or having a full node sequencer or aggregator do so on their behalf. Let’s talk about how contracts interact between L1 and L2--how an L1 contract calls an L2 contract, and vice versa.
The L1 and L2 chains run asynchronously from each other, so it is not possible to make a cross-chain call that produces a result within the same transaction as the caller. Instead, cross-chain calls must be asynchronous, meaning that the caller submits the call at some point in time, and the call runs later. As a consequence, a cross-chain contract-to-contract call can never produce a result that is available to the calling contract (except for acknowledgement that the call was successfully submitted for later execution).
L1 contracts can submit L2 transactions
An L1 contract can submit an L2 transaction, just like a user would, by calling the EthBridge. This L2 transaction will run later, producing results that will not be available to the L1 caller. The transaction will execute at L2, but the L1 caller won’t be able to see any results from the L2 transaction.
The advantage of this method is that it is simple and has relatively low latency. The disadvantage, compared to the other method we’ll describe soon, is that the L2 transaction might revert if the L1 caller doesn’t get the L2 gas price and max gas amount right. Because the L1 caller can’t see the result of its L2 transaction, it can’t be absolutely sure that its L2 transaction will succeed.
This would introduce a serious a problem for certain types of L1 to L2 interactions. Consider a transaction that includes depositing a token on L1 to be made available at some address on L2. If the L1 side succeeds, but the L2 side reverts, you've just sent some tokens to the L1 inbox contract that are unrecoverable on either L2 or L1. Not good.
L1 to L2 ticket-based transactions
Fortunately, we have another method for L1 to L2 calls, which is more robust against gas-related failures, that uses a ticket-based system. The idea is that an L1 contract can submit a “pre-packaged” transaction and immediately receive a “ticketID” that identifies that submission. Later, anyone can call a special pre-compiled contract at L2, providing the ticketID, to try redeeming the ticket and executing the transaction.
The pre-packaged transaction includes the sender’s address, a destination address, a callvalue, and calldata. All of this is saved, and the callvalue is deducted from the sender’s account and (logically) attached to the pre-packaged transaction.
If the redemption succeeds, the transaction is done, a receipt is issued for it, and the ticketID is canceled and can’t be used again. If the redemption fails, for example because the packaged transaction fails, the redemption reports failure and the ticketID remains available for redemption.
As an option (and by default), the original submitter can try to redeem their submitted transaction immediately, at the time of its submission, in the hope that this redemption will succeed. As an example, our "token deposit" use case above should, in the happy, common case, still only require a single signature from the user. If this instant redemption fails, the ticketID will still exist as a backstop which others can redeem later.
Submitting a transaction in this way carries a price in ETH which the submitter must pay, which varies based on the calldata size of the transaction. Once submitted, the ticket is valid for about a week. It will remain valid after that, as long as someone pays weekly rent to keep it alive. If the rent goes unpaid and the ticket has not been redeemed, it is deleted.
When the ticket is redeemed, the pre-packaged transaction runs with sender and origin equal to the original submitter, and with the destination, callvalue, and calldata the submitter provided at the time of submission. (The submitter can specify an address to which the callvalue will be refunded if the transaction is dropped for lack of rent without ever being redeemed.)
This rent-based mechanism is a bit more cumbersome than direct L1 to L2 transactions, but it has the advantage that the submission cost is predictable and the ticket will always be available for redemption if the submission cost is paid. As long as there is some user who is willing to redeem the ticket (and pay rent if needed), the L2 transaction will eventually be able to execute and will not be silently dropped.
L2 to L1 ticket-based calls
Calls from L2 to L1 operate in a similar way, with a ticket-based system. An L2 contract can call a method of the precompiled ArbSys contract, to send a transaction to L1. When the execution of the L2 transaction containing the submission is confirmed at L1 (some days later), a ticket is created in the EthBridge. That ticket can be triggered by anyone who calls a certain L1 EthBridge method and submits the ticketID. The ticket is only marked as redeemed if the L1 transaction does not revert.
These L2-to-L1 tickets have unlimited lifetime, until they’re successfully redeemed. No rent is required, as the costs are covered by network fees that are collected elsewhere in Arbitrum.
Gas and Fees
ArbGas is used by Arbitrum to track the cost of execution on an Arbitrum chain. It is similar in concept to Ethereum gas, in the sense that every Arbitrum Virtual Machine instruction has an ArbGas cost, and the cost of a computation is the sum of the ArbGas costs of the instructions in it.
ArbGas is not directly comparable to Ethereum gas. In general an Arbitrum chain can consume many more ArbGas units per second of computation, compared to the number of Ethereum gas units in Ethereum's gas limit. Developers and users should think of ArbGas as much more plentiful and much cheaper per unit than Ethereum gas.
[A note on terminology: In reality, there are two related notions of gas in Arbitrum: AVM gas which is tracked by the virtual machine execution, and ArbGas which is used in the API. The two are strictly related because 1 ArbGas = 100 AVM gas. To simplify the discussion, this section uses the single term ArbGas and ignores the factor-of-100 conversions that are done correctly by the Arbitrum code.]
Why ArbGas?
One of the design principles of the Arbitrum Virtual Machine (AVM) is that every instruction should take a predictable amount of time to validate, prove, and proof-check. As a corollary, we want a way to count or estimate the time required to validate any computation.
There are two reasons for this. First, we want to ensure that proof-checking has a predictable cost, so we can predict how much L1 gas is needed by the EthBridge and ensure that the EthBridge will never come anywhere close to the L1 gas limit.
Second, accurate estimation of validation time is important to maximize the throughput of a rollup chain, because it allows us to set the chain's speed limit safely.
ArbGas in rollup blocks
Every rollup block includes an amount of ArbGas used by the computation so far, which implies an amount used since the predecessor rollup block. Like everything else in the rollup block, this value is only a claim made by the staker who created the block, and the block will be defeatable in a challenge if the claim is wrong.
Although the ArbGas value in a rollup block might not be correct, it can be used reliably as a limit on how much computation is required to validate the block. This is true because a validator who is checking the block can cut off their computation after that much ArbGas has been consumed; if that much ArbGas has been consumed without reaching the end of the rollup block, then the rollup block must be wrong and the checker can safely challenge it. For this reason, the rollup protocol can safely use the ArbGas claim in a rollup block, minus the amount in the predecessor block, as an upper bound on the time required to validate the rollup block’s correctness.
A rollup block can safely be challenged even if the ArbGas usage is the only aspect of the block that is false. When a claim is bisected, the claims will include (claimed) ArbGas usages, which must sum to the ArbGas usage of the parent claim. It follows that if the claim's ArbGas amount is wrong, at least one of the sub-claims must have a wrong ArbGas amount. So a challenger who knows that a claim's ArbGas amount is wrong will always be able to find a sub-claim that has a wrong ArbGas amount.
Eventually the dispute will get down to a single AVM instruction, with a claim about that instruction's ArbGas usage. One-step proof verification checks if this claim is correct. So a wrong ArbGas claim in a rollup block can be pursued all the way down to a single instruction with a wrong ArbGas amount--and then the wrongness will be detected by the one-step proof verification in the EthBridge.
ArbGas accounting in the AVM
The AVM architecture also does ArbGas accounting internally, using a machine register called AVM Gas Remaining, which is a 256-bit unsigned integer that behaves as follows:
- The register is initially set to MaxUint256.
- Immediately before any instruction executes, that instruction's AVM gas cost is subtracted from the register. If this would make the register's value less than zero, an error is generated and the register's value is set to MaxUint256. (The error causes a control transfer as specified in the AVM specification.)
- A special instruction can be used to read the register's value.
- Another special instruction can be used to set the register to any desired value.
This mechanism allows ArbOS to control and account for the ArbGas usage of application code. ArbOS can limit an application call's use of ArbGas to N units by setting the register to N before calling the application, then catching the out-of-ArbGas error if it is generated. At the beginning of the runtime's error-handler, ArbOS would read the AVM Gas Remaining register, then set the register to MaxUint256 to ensure that the error-handler could not run out of ArbGas. If the read of the register gave a value close to MaxInt256, then it must be the case that the application generated an out-of-ArbGas error. (It could be the case that the application generates a different error while a small amount of ArbGas remains, then an out-of-ArbGas error occurs at the very beginning of the error-handler. In this case, the second error would set the AVM Gas Remaining register to MaxInt256 and throw control back to the beginning of the error-handler, causing the error-handler to conclude that an out-of-ArbGas error was caused by the application. This is a reasonable behavior which we will consider to be correct.)
If the application code returns control to the runtime without generating an out-of-ArbGas error, the runtime can read the AVM Gas Remaining register and subtract to determine how much ArbGas the application call used. This can be charged to the application's account.
The runtime can safely ignore the ArbGas accounting mechanism. If the special instructions are never used, the register will be set to MaxInt256, and will decrease but in practice will never get to zero, so no error will ever be generated.
The translator that turns EVM code into equivalent AVM code will never generate the instruction that sets the ArbGasRemaining register, so untrusted code cannot manipulate its own gas allocation.
The Speed Limit
The security of Arbitrum chains depends on the assumption that when one validator creates a rollup block, other validators will check it and issue a challenge if it is wrong. This requires that the other validators have the time and resources to check each rollup block in time to issue a timely challenge. The Arbitrum protocol takes this into account in setting deadlines for rollup blocks.
This sets an effective speed limit on execution of an Arbitrum VM: in the long run the VM cannot make progress faster than a validator can emulate its execution. If rollup blocks are published at a rate faster than the speed limit, their deadlines will get farther and farther in the future. Due to the limit, enforced by the rollup protocol contracts, on how far in the future a deadline can be, this will eventually cause new rollup blocks to be slowed down, thereby enforcing the effective speed limit.
Being able to set the speed limit accurately depends on being able to estimate the time required to validate an AVM computation, with some accuracy. Any uncertainty in estimating validation time will force us to set the speed limit lower, to be safe. And we do not want to set the speed limit lower, so we try to enable accurate estimation.
Fees
User transactions pay fees, to cover the cost of operating the chain. These fees are assessed and collected by ArbOS at L2. They are denominated in ETH. Some of the fees are immediately paid to the aggregator who submitted the transaction (if there is one, and subject to some limitations discussed below). The rest go into a network fee pool that is used to pay service providers who help to enable the chain’s secure operation, such as validators.
Fees are charged for four resources that a transaction can use:
- L2 tx: a base fee for each L2 transaction, to cover the cost of servicing a transaction
- L1 calldata: a fee per units of L1 calldata directly attributable to the transaction (as on Ethereum, each non-zero byte of calldata is 16 units, and each zero byte of calldata is 4 units)
- computation: a fee per unit of ArbGas used by the transaction
- storage: a fee per location of EVM contract storage, based change in EVM storage usage due to the transaction
Each of these four resources has a price, which may vary over time. The resource prices, which are denominated in ETH (more precisely, in wei), are set as follows:
Prices for L2 tx and L1 calldata
The prices of the first two resources, L2 tx and L1 calldata, depend on the L1 gas price. ArbOS can’t directly see the L1 gas price, so it estimates the L1 gas prices, based on the L1 Ethereum base fee paid by certain recent EthBridge transactions.
- The base price of an L2 transaction is set by each aggregator, using an Arbitrum precompile, subject to a system-wide maximum.
- The base price of a unit of L1 calldata is just the estimated L1 gas price.
If the transaction was submitted by an aggregator, ArbOS collects these base fees for L2 tx and L1 calldata, and credits that amount immediately to the aggregator. ArbOS also adds a 15% markup and deposits those funds into the network fee account, to help cover overhead and other chain costs. If the transaction was not submitted by an aggregator, ArbOS collects only the 15% portion and credits that to the network fee account.
In order for an aggregator to be reimbursed for submitting a transaction, three things must be true:
- The transaction’s nonce is correct. [This prevents an aggregator from resubmitting a transaction to collect multiple reimbursements for it.]
- The transaction’s sender has ETH in its L2 account to pay the fees.
- The aggregator is listed as the sender’s “preferred aggregator”. (ArbOS records a preferred aggregator for each account, with the default being a specific aggregator address. On Arbitrum One, the default aggregator is the sequencer run by Offchain Labs.) [The preferred aggregator mechanism prevents an aggregator from front-running another aggregator’s batches to steal its reimbursements.]
If these conditions are not all met, the transaction is treated as not submitted by an aggregator so only the network fee portion of the fee is collected.
Price for storage
Transactions are charged a storage fee for allocating an EVM storage cell. (Here, "allocating" means changing the value in a cell from zero to a non-zero value, and "deallocating" means changing a cell from a non-zero to a zero value.) If a cell was allocated within a transaction, and is later deallocated within the same transaction, the allocation fee will be refunded when the transaction completes.
Contract creation is charged one storage fee for every 32 bytes of code in the contract. However, if a newly created contract has the same deployed code as an already existing contract, ArbOS will usually detect this and keep only a single copy of the code, thereby saving the second contract from having to pay for code storage.
Each storage allocation costs 2000 times the estimated L1 gas price. This means that storage costs about 10% as much as it does on the L1 chain.
Price for ArbGas
ArbGas pricing depends on a minimum price, and a congestion pricing mechanism.
The minimum ArbGas price is set equal to the estimated L1 gas price divided by 100. The price of ArbGas will never go lower than this.
The price will rise above the minimum if the chain is starting to get congested. The idea is similar to Ethereum, to deal with a risk of overload by raising the price of gas enough that demand will meet supply. The mechanism is inspired by Ethereum’s EIP-1559, which uses a base price that, at the beginning of each block, is multiplied by a factor between 7/8 and 9/8, depending on how busy the chain seems to be. When the demand seems to be exceeding supply, the factor will be more than 1; when supply exceeds demand, the factor will be less than 1. (But the price never goes below the minimum.)
The automatic adjustment mechanism depends on an “ArbGas pool” that is tracked by ArbOS. The ArbGas pool has a maximum capacity that is equal to 12 minutes of full-speed computation at the chain’s speed limit. ArbGas used by transactions is subtracted from the gas pool, and at the beginning of each new Ethereum block, ArbGas is added to the pool corresponding to full-speed execution for the number of timestamp seconds since the last block (subject to the maximum pool capacity).
After adding the new gas to the pool, if the new gas pool size is G, the current ArbGas price is multiplied by (16200S - G) / (14400S) where S is the ArbGas speed limit of the chain. This quantity will be 7/8 when G = 720S (the maximum gas pool size) and it will be 9/8 when G = 0.
The congestion limit
The gas pool is also used to limit the amount of gas available to transactions at a particular timestamp. In particular, if a transaction could require more gas than is available in the gas pool, that transaction is rejected without being executed, returning a transaction receipt indicating that the transaction was dropped due to congestion. This prevents the chain from building up a backlog that is very long--if transactions are being submitted consistently faster than they can be validated, eventually the gas pool will become empty and transactions will be dropped. Meanwhile the transaction price will be escalating, so that the price mechanism will be able to bring supply and demand back into alignment.
ArbGas accounting and the second-price auction
As on Ethereum, Arbitrum transactions submit a maximum gas amount (here, “maxgas” for short) and a gas price bid (here, “gasbid” for short). A transaction will use up to its maxgas amount of gas, or will revert if more gas would be needed.
On Ethereum, the gas price paid by a transaction is equal to its gasbid. Arbitrum, by contrast, treats the gasbid as the maximum amount the transaction is willing to pay for gas. The actual price paid is equal to the current Arbitrum ArbGas price, whatever that is, as long as it is less than or equal to the transaction’s gasbid. If the transaction’s gasbid is less than the current Arbitrum gas price, the transaction is dropped and a transaction receipt issued, saying that the transaction’s gasbid was too low.
So Arbitrum transactions shouldn’t try to “game” their gasbid by trying to match it too closely to the current ArbGas price. Instead, transactions should set their gasbid equal to the maximum price they’re willing to pay for ArbGas, with the caveat that the sender must have at least gasbid*maxgas in its L2 ETH account.